Speed up your MFC program without a profiler!
I’m going to explain how to potentially improve the performance of MFC programs using CMap<> and related containers (CMapStringToPtr, etc) by a substantial amount.
We use MFC for quite a lot of our software. We also use STL and also some custom containers. It is easy to fall into certain programming habits of using a particular container for a particular task. Sometimes the result is not what you expected!
During the Christmas break I decided to write some software to analyse the Software Verification website log files. Initially I wanted to do keyword mining, but it soon blossomed into a stats package calculating different statistics for keywords, referrers, domains, URLs, favourite domains, bounce rates, evaluation download rates, etc.
I was also reading the wonderful “Web Analytics an Hour a Day” book by Avinash Kauschik. And to top it all, I was ill. I’ve since been told by various people that I had Swine Flu.
The initial version didn’t calculate much and was quite fast, but when I wanted to scale up to calculating monthly data as well as yearly, that was 13 times as much calculation and the inefficiencies in container choice started to show. I’d been lazy, this was a hobby project, nothing serious, so I’d chosen the MFC class CMap.
I wanted to map keyword strings to countData objects which would hold all the data on that keyword. Later we could discard the map and just use an array of keyword objects for random access and sorting. I wanted data for unique keywords, so during processing of the data it seemed natural to want to map the keyword to the keyword data. I was doing similar things for referrers, referring domains, requested URLs, etc.
A CMap<> is an MFC hash table. A declaration would look like this:
CMap<CString, LPCTSTR, countData *, countData *&> mfcData;
The data processing would be something like this (simplified)
BOOL b;
while(TRUE)
{
CString s;
b = file.ReadString(s);
if (!b)
break;
// lookup string
countData *cd = NULL;
if (mfcData.Lookup(s, cd))
{
// if we know about the string update the count
cd->addCount(1);
}
else
{
// otherwise create the string and update the count
cd = new countData(s, 1);
mfcData.SetAt(s, cd);
}
}
The problem with the CMap<> class is that its hash key calculation isn’t very sophisticated, so you get collisions reasonably quickly, which forces the CMap to start making linked lists for the non-identical collisions, and walking the linked lists for subsequent searches is linear time. That gets slower as you add more data.
After processing for one particlularly large set of data for 2009 took 36 hours I thought a better solution was required. Why did I let it run so long? Partly because once it got past a few hours I was curious to see how long it would take. By this time I was ill, so it didn’t really matter, I was spending much of this time in bed alternately too hot or too cold 🙁
The STL has a non-standard hash table, so we didn’t want to use that, so we opted to use the STL <map> class. The declaration would look like this
map<CString, countData *> stlData;
The data processing would be something like this (simplified)
BOOL b;
while(TRUE)
{
if (stopScan)
break;
CString s;
b = file.ReadString(s);
if (!b)
break;
// lookup string
MAP_STL::iterator iter;
iter = stlData.find(s);
if (iter != stlData.end())
{
// if we know about the string update the count
iter->second->addCount(1);
}
else
{
// otherwise create the string and update the count
countData *cd;
cd = new countData(s, 1);
stlData[s] = cd;
}
}
This is not a hash table, its a B-tree, so it will use more memory than the hash map, and unique entries should be slower than the hash table, but colliding entries should be faster. With this new style of map substituted all over the program, for all the many unique datatypes being calculated, the processing time dropped from 36 hours to 1 hour.
In other words, the STL version processed the data in 2.77% of the time the MFC version processed the data. That is a 97% improvement in processing time.
I am not saying that you will get this improvement. This improvement was acheived partly because of the type of statistics being calculated and partly due to the input data having so many collisions. The dataset for the above test was 17.1GB of Apache log files.
I have created an example MFC program that shows a trivial example of reading in lines from a file, testing them for uniqueness and storing them and updating the counts for them. The program also does the same using STL. Some sample times shown below:
| Size (MB) | MFC | STL | Improvement |
|---|---|---|---|
| 34 | 00:00:12 | 00:00:06 | 50% |
| 2048 | 00:22:46 | 00:05:21 | 76% |
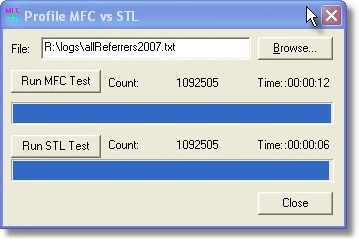
For a sample 34MB input file, the MFC program processes the data in 12+ seconds and the STL program processes the same data in 6+ seconds. An approximately 50% improvement.
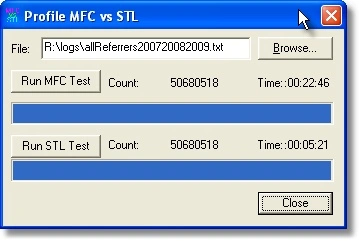
For a sample 2GB input file, the MFC program processes the data in 22 minutes 46 seconds seconds and the STL program processes the same data in 5 minutes 21 seconds. An approximately 76% improvement.
The larger the dataset, or the more different CMap<> you are using calculating the data, the chances are that changing them to STL <map> would be highly effective in speeding up that part of your application. Note that if you are only loading a few tens of items into the map, it will not be worth making the change.
You can download the executable and the source code with project files so that you can test this yourself.
I don’t recommend changing all occurrences of CMap<> for STL <map>, but changing the right ones should make some easy and worthwhile gains for you.